新闻公告
学院资讯
元深夜开源骆驼4! Moe是第一次采用的,具有惊人
作者:365bet体育日期:2025/04/08 浏览:
 报告机器编辑部门核心的机器的核心是出乎意料的。 Meta选择在周末发布最新的AI模型系列Llama 4,这是Llama家族的最新成员。该系列包括Llama 4 Scout,Llama 4 Maverick和Llama 4 Ememoth。所有这些模型都经过大量非文本,视频图像和数据的培训,以使它们具有广泛的视觉理解。 Llama 4 Meta Genai的负责人艾哈迈德·达勒(Ahmad al-Dahle)表示,长期元的承诺打开AI资源,AI社区的整个开源,以及对开放系统将产生最好的小型,中等和即将到来的切割模型的不懈信念。 Google的首席执行官Pichai不禁呼吸,人工智能的世界永远不会感到无聊。 Binabati参见Llama Team 4,继续前进!扩展全文
在竞技场中,美洲驼4小牛队排名第二,这成为第四个大型模型,达到1400分。其中,开放模型是Previ排名不过,不仅仅是深deepseek;首先是艰难的词,编程,数学,创意写作和其他活动;它大大超过了自己的美洲驼3 405B,其商标从1268年提高到1417年;和样式控制中的第五级排名。
那么,Llama Model系列4的特征是什么?具体来说:
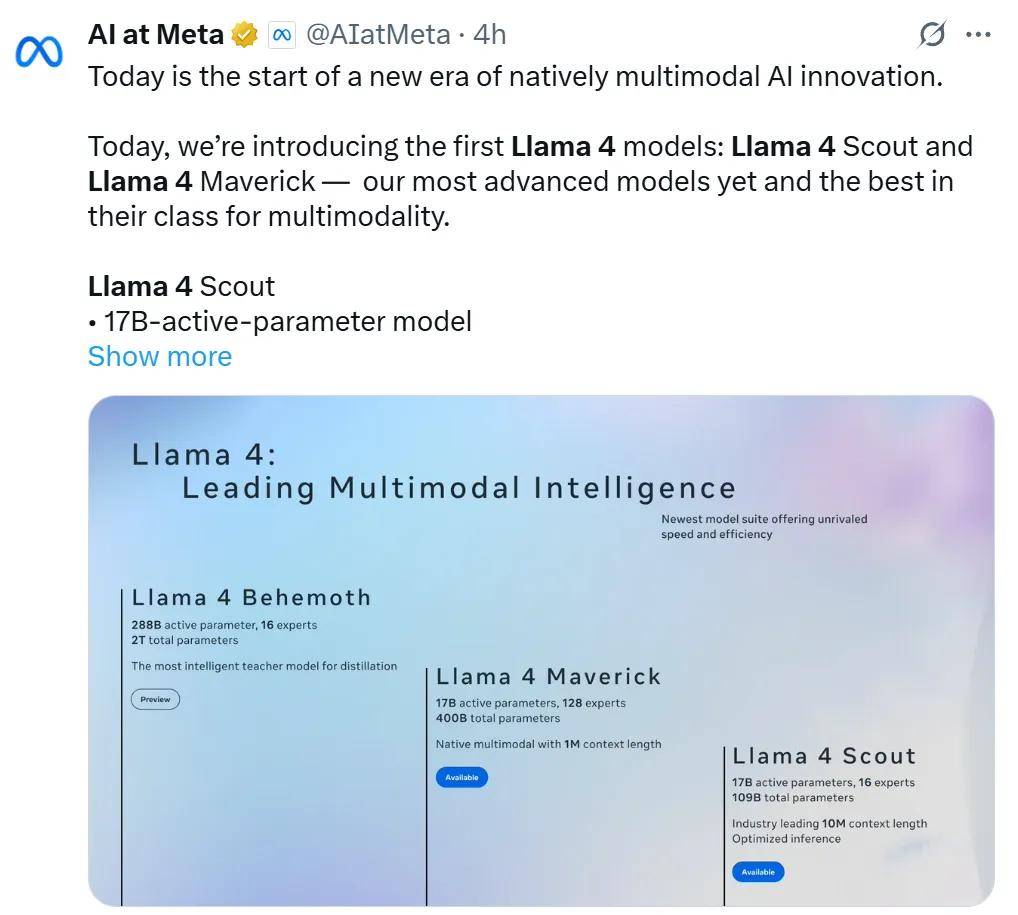
Llama 4 Scout是一种具有170亿个激活参数和16位专家的模型。这是其类别中最好的多模式模型,比前几代Llama模型强,并且可以适应单个NVIDIA H100 GPU。此外,Llama 4侦察兵提供了导致10M上下文行业的窗口,Gemma 3优于3,Gemini 2.0 Flash-lite和Mistral 3.1,以广泛报道的基准。
Llama 4 Maverick是128位,170亿型激活参数的专家,这是其类型的最佳多模式模型,击败GPT-4O和Gemini 2.0 2.0 Flash具有广泛报道的基准测试,同时在识别新的DeepSeek V3中获得了可比的结果编程不到参数激活的一半。 Llama 4 Maverick提供了一流的物有所值,以及实验性的聊天版本,其Elo Mark在Lmarena中为1417。
以上两个模型是至今最好的元模型,这主要是因为它们能够使用2880亿个激活参数的美洲驼,而16个专家4庞然大镜模型与知识蒸馏。
Llama 4庞然大物是目前最强的元模型,也是世界上最聪明的大语言模型之一。 Llama 4 Behemoth改变了GPT-4.5,Claude 3.7十四行诗和Gemini 2.0 Pro在科学,技术,工程和数学(STEM)的几个基准上。
但是,Llama 4 Bememoth仍在实践中,许多内容将在下一个META中发布。
好消息是,用户现在可以在Llama.com和Hug上下载Llama 4 Scout和Llama 4 Maverick的最新型号。
所有Llama 4型号都是本机的多模式设计,例如上传图像,您可以询问关于此图像的任何问题
Llama 4侦察兵支持多达1000万个令牌环境,这是当今行业的最长时间,将新的使用案例围绕记忆,个性化和多模式的应用程序结合在一起。
Llama 4也是图像接地的一流,能够与相关的视觉概念和图像区域中的锚模型响应对齐。
Llama 4是最初且组织良好的,可以理解12种语言的无与伦比的文本,从而支持全球发展和扩展。
预训练
在构建下一代Llama模型时,Meta在训练前阶段测试了一些新技术。
首先,这是Meta首次采用专家建筑(MOE)。在MOE模型中,单个令牌仅是总参数的一个部分。梅塔(Metas。
以1个小牛为例,以170亿个激活参数和4000亿个总参数为例。 Meta使用交替的密集层和混合专家(MOE)的层来提高识别效率。在MOE层中,他们使用了128位路由专家和一家股票专家。每个代币都被发送给共享专家和128位路由专家之一。
因此,尽管所有参数都存储在存储器中,但在使用这些模型时,只有一部分总参数被激活。它通过减少模型和延迟服务来提高理解效率-LALA 4小牛可以遇到单个NVIDIA H100 DGX主机,以便于部署,并且还可以通过共享识别来实现最高效率。
Llama 4系的Modelo采用了本机多模式设计,通过早期融合将文本和视觉令牌无缝整合到新娘模型中。早期融合是一个重大进步,因为它允许使用模型的联合预培训大量非生成文本,图像和视频数据。此外,META改进了Llama 4上的视觉编码器,该编码器基于MetaClip,以更好地调整编码器为LLM。
此外,元数据还开发了一种称为Metap的新训练技术,该技术可以可靠地设置高参数模型,例如研究率并开始对每一层的规模启动。 Meta发现,所选的超参数在不同的批次大小,模型宽度,深度和训练令牌值之间具有巨大的移动。
SupportSllama 4是通过200种语言的预培训(包括100多种语言)的开源调整工作的开源,每种语言都超过10亿代币,这是多语言代币的10倍,是Llama 3总体上的10倍。
此外,具有FP8准确性的元火车既有质量又可以确保大量使用失败。使用FP8和32K GPU预先训练Llama 4庞然大物模型时,META每GPU实现390个TFLOPS。用于培训的数据组合的总数更多超过300万亿个令牌,是Llama 3预训练数据的数据混合量的两倍以上,涵盖了不同的文本数据,图像和视频。
最后,元数据继续通过SO估算的中期训练来练习模型,从而提高了模型的基本功能,包括具有专门数据集的扩展长上下文。这使得元可以解锁Llama 4侦察兵的1000万个输入上下文的顶级行业,同时提高模型的质量。
训练后
Llama 4 Maverick提供了无与伦比的表现,从而导致该行业理解图像和文本,从而创建了涵盖语言障碍的复杂AI应用程序。作为通用助理和聊天用例的产品驱动模型,Llama 4 Maverick不仅是对图像和创意写作的准确了解。
当Llama 4 Maverick模型是训练后的时,最大的挑战是平衡许多投入,推理和对话能力的方式。混合模态S,元设计设计了一种良好的课程方法,与单局专家模型相比,该方法在性能上并不困扰。
在Llama 4中,META通过采用各种技术来全面改进培训过程:轻巧监督的微调(SFT)在线增强学习(RL)轻量级直接直接对偏好(DPO)。 Meta发现SFT和DPO可能是过度构造的模型,从而限制了探索在线RL阶段的能力,从而降低了推理,编程和数学领域的准确性。
为了解决这个问题,Meta使用Llama模型作为酌处权,删除了以上标记的数据的50%以上,并在剩余的困难数据集上执行了轻巧的微调(SFT)。在随后的多模式在线增强学习(RL)的阶段,通过选择更困难的信号,可以通过选择更加困难的信号来取得重大改进。
此外,元启动者TED对在线RL进行了连续的方法,该方法交替练习该模型,并使用它继续过滤和维护中等至高的贫困线索。在计算和准确性权衡方面,这种方法非常有用。
最后,Meta还进行了轻巧的直接偏好(DPO),以处理与模型响应质量有关的边缘案例,从而有效地在智能和对话模型功能的功能之间取得了良好的平衡。这些改进导致了该行业的领先通用聊天模式,并具有最先进的智能和图像理解。
表现
Llama 4 Maverick包含170亿个激活参数,128个专家和4000亿个甲甲,其以低于Llama 3.3 70B的价格提供了更高的质量。从下表可以看出,Llama 4 Maverick是同类产品中最好的多模式模型。它的性能超过了类似的模型,例如带有EN的GPT-4O和Gemini 2.0在编码和识别方面,编码和识别,多语言,长上下文和图像基准以及更大的DeepSeek v3.1竞争。
较小的Llama 4 Scout是一种通用模型,具有170亿个激活参数,16位专家和1009亿个总参数,可提供其类别中最先进的性能。 Llama 4 Scout将支持的背景从Llama 3的128K提高到了1000万个令牌的领先。这为应用程序摘要等应用程序提供了更多可能的可能性,解析了广泛的用户活动以实现个性化的任务,并指出了大型代码库。
Llama 4 Scout在训练和训练后都使用256K上下文长度,提供了强大的整体上下文功能的基本模型。在诸如在干草堆上找到针的活动中,该模型显示出令人信服的结果。
Llama 4结构的主要变化之一是使用相互关联通过扫描推理温度,没有出现位置的调节层,并增强了长期上下文化功能。该体系结构称为Irrope Architecture,在该体系结构中,我代表一个连贯的注意力层,它使其支持它支持长期目标,而无需限制上下文。绳索是指大多数层旋转位置的牙龈。
Meta在图像和视频帧中广泛训练了这两个模型仍然图像,以使它们具有广泛的视觉理解,包括了解时序活动和相关图像。这使模型可以轻松地执行具有多图像输入和文本信号的视觉推理和理解任务。这些模型在假装过程中最多支持48张图像,并且可以在训练后支持8张图像,并取得出色的结果。
Llama 4侦察兵不仅仅是定位图像,还将用户信号与相关的视觉概念和模型模型的响应对齐图像中的区域。这允许大型语言模型精确地执行视觉Q&Amore,最好了解用户的目标并找到有趣的事物。
此外,Llama 4 Scout不仅仅是相似的编码模型,推论,长上下文和图像基准,而且比以前的Llama模型更好。
推动新范围推送骆驼:2T庞然大物
Llama 4庞然大物的预览是一种教师模型和专门的多模式混合模型,具有2880亿个激活参数,16位专家和约2万亿个参数。
它在数学,多语言和图像基准中提供了非熟思模型的最先进性能,非常适合教较小的骆驼模型4。
培训后具有两万亿个参数的模型是一个巨大的挑战,它要求研究人员完全重新设计和改善从数据量表开始的现行程序。为了最大程度地提高性能,元必须修剪95%的管理曲调(SFT)数据对于较小型号的d到50%的修剪比。此举是为了在质量和效率之间达到所需的平衡。 Meta还发现,轻巧的微调(SFT)第一和大型增强研究(RL)可以显着提高对模型能力和编码的认识。
META的强化学习方法(RL)通过接触策略模型,增加难度增加的提示,以及在发展逐渐增加难度的培训课程中,重点关注@K评论的通过。此外,在训练过程中,零效率线索是动态过滤的,并且已经建立了许多包含许多您的培训的培训,这在数学,推理和编码方面为模型带来了显着改善的性能。最后,从多个系统指令中猛烈抨击对于确保模型保持遵守理解和编码任务的坚持至关重要,从而使模型可以执行在各种任务中很好。
扩大研究(RL)研究的研究(RL)也是一个主要的挑战,迫使元元素重新设计和改善刺激强化以应对前所未有的规模的基础结构。
元将优化混合专家(MOE)的相似性以提高速度,从而加速差异过程。此外,他们在在线研究上开发了一个完全不寻常的培训框架,以改善技能。与现有的分布式培训框架相比,牺牲内存以将所有模型加载到内存中,新的元基础架构可以灵活地在不同的GPU中提供不同的模型,并且基于计算速度的许多模型之间的资源平衡和资源平衡。与上一代相比,这种创新的培训效率提高了近10倍。
Llama 4 Scout和Llama 4 Maverick现在可以下载到:
llama.com:https://www.llama.com/llama-lane下载/
拥抱面孔地址:https://huggingface.co/meta-llama
参考参考:https://ai.meta.com/blog/llama-4-gultimodal-telligence/return to sohu以查看更多信息
报告机器编辑部门核心的机器的核心是出乎意料的。 Meta选择在周末发布最新的AI模型系列Llama 4,这是Llama家族的最新成员。该系列包括Llama 4 Scout,Llama 4 Maverick和Llama 4 Ememoth。所有这些模型都经过大量非文本,视频图像和数据的培训,以使它们具有广泛的视觉理解。 Llama 4 Meta Genai的负责人艾哈迈德·达勒(Ahmad al-Dahle)表示,长期元的承诺打开AI资源,AI社区的整个开源,以及对开放系统将产生最好的小型,中等和即将到来的切割模型的不懈信念。 Google的首席执行官Pichai不禁呼吸,人工智能的世界永远不会感到无聊。 Binabati参见Llama Team 4,继续前进!扩展全文
在竞技场中,美洲驼4小牛队排名第二,这成为第四个大型模型,达到1400分。其中,开放模型是Previ排名不过,不仅仅是深deepseek;首先是艰难的词,编程,数学,创意写作和其他活动;它大大超过了自己的美洲驼3 405B,其商标从1268年提高到1417年;和样式控制中的第五级排名。
那么,Llama Model系列4的特征是什么?具体来说:
Llama 4 Scout是一种具有170亿个激活参数和16位专家的模型。这是其类别中最好的多模式模型,比前几代Llama模型强,并且可以适应单个NVIDIA H100 GPU。此外,Llama 4侦察兵提供了导致10M上下文行业的窗口,Gemma 3优于3,Gemini 2.0 Flash-lite和Mistral 3.1,以广泛报道的基准。
Llama 4 Maverick是128位,170亿型激活参数的专家,这是其类型的最佳多模式模型,击败GPT-4O和Gemini 2.0 2.0 Flash具有广泛报道的基准测试,同时在识别新的DeepSeek V3中获得了可比的结果编程不到参数激活的一半。 Llama 4 Maverick提供了一流的物有所值,以及实验性的聊天版本,其Elo Mark在Lmarena中为1417。
以上两个模型是至今最好的元模型,这主要是因为它们能够使用2880亿个激活参数的美洲驼,而16个专家4庞然大镜模型与知识蒸馏。
Llama 4庞然大物是目前最强的元模型,也是世界上最聪明的大语言模型之一。 Llama 4 Behemoth改变了GPT-4.5,Claude 3.7十四行诗和Gemini 2.0 Pro在科学,技术,工程和数学(STEM)的几个基准上。
但是,Llama 4 Bememoth仍在实践中,许多内容将在下一个META中发布。
好消息是,用户现在可以在Llama.com和Hug上下载Llama 4 Scout和Llama 4 Maverick的最新型号。
所有Llama 4型号都是本机的多模式设计,例如上传图像,您可以询问关于此图像的任何问题
Llama 4侦察兵支持多达1000万个令牌环境,这是当今行业的最长时间,将新的使用案例围绕记忆,个性化和多模式的应用程序结合在一起。
Llama 4也是图像接地的一流,能够与相关的视觉概念和图像区域中的锚模型响应对齐。
Llama 4是最初且组织良好的,可以理解12种语言的无与伦比的文本,从而支持全球发展和扩展。
预训练
在构建下一代Llama模型时,Meta在训练前阶段测试了一些新技术。
首先,这是Meta首次采用专家建筑(MOE)。在MOE模型中,单个令牌仅是总参数的一个部分。梅塔(Metas。
以1个小牛为例,以170亿个激活参数和4000亿个总参数为例。 Meta使用交替的密集层和混合专家(MOE)的层来提高识别效率。在MOE层中,他们使用了128位路由专家和一家股票专家。每个代币都被发送给共享专家和128位路由专家之一。
因此,尽管所有参数都存储在存储器中,但在使用这些模型时,只有一部分总参数被激活。它通过减少模型和延迟服务来提高理解效率-LALA 4小牛可以遇到单个NVIDIA H100 DGX主机,以便于部署,并且还可以通过共享识别来实现最高效率。
Llama 4系的Modelo采用了本机多模式设计,通过早期融合将文本和视觉令牌无缝整合到新娘模型中。早期融合是一个重大进步,因为它允许使用模型的联合预培训大量非生成文本,图像和视频数据。此外,META改进了Llama 4上的视觉编码器,该编码器基于MetaClip,以更好地调整编码器为LLM。
此外,元数据还开发了一种称为Metap的新训练技术,该技术可以可靠地设置高参数模型,例如研究率并开始对每一层的规模启动。 Meta发现,所选的超参数在不同的批次大小,模型宽度,深度和训练令牌值之间具有巨大的移动。
SupportSllama 4是通过200种语言的预培训(包括100多种语言)的开源调整工作的开源,每种语言都超过10亿代币,这是多语言代币的10倍,是Llama 3总体上的10倍。
此外,具有FP8准确性的元火车既有质量又可以确保大量使用失败。使用FP8和32K GPU预先训练Llama 4庞然大物模型时,META每GPU实现390个TFLOPS。用于培训的数据组合的总数更多超过300万亿个令牌,是Llama 3预训练数据的数据混合量的两倍以上,涵盖了不同的文本数据,图像和视频。
最后,元数据继续通过SO估算的中期训练来练习模型,从而提高了模型的基本功能,包括具有专门数据集的扩展长上下文。这使得元可以解锁Llama 4侦察兵的1000万个输入上下文的顶级行业,同时提高模型的质量。
训练后
Llama 4 Maverick提供了无与伦比的表现,从而导致该行业理解图像和文本,从而创建了涵盖语言障碍的复杂AI应用程序。作为通用助理和聊天用例的产品驱动模型,Llama 4 Maverick不仅是对图像和创意写作的准确了解。
当Llama 4 Maverick模型是训练后的时,最大的挑战是平衡许多投入,推理和对话能力的方式。混合模态S,元设计设计了一种良好的课程方法,与单局专家模型相比,该方法在性能上并不困扰。
在Llama 4中,META通过采用各种技术来全面改进培训过程:轻巧监督的微调(SFT)在线增强学习(RL)轻量级直接直接对偏好(DPO)。 Meta发现SFT和DPO可能是过度构造的模型,从而限制了探索在线RL阶段的能力,从而降低了推理,编程和数学领域的准确性。
为了解决这个问题,Meta使用Llama模型作为酌处权,删除了以上标记的数据的50%以上,并在剩余的困难数据集上执行了轻巧的微调(SFT)。在随后的多模式在线增强学习(RL)的阶段,通过选择更困难的信号,可以通过选择更加困难的信号来取得重大改进。
此外,元启动者TED对在线RL进行了连续的方法,该方法交替练习该模型,并使用它继续过滤和维护中等至高的贫困线索。在计算和准确性权衡方面,这种方法非常有用。
最后,Meta还进行了轻巧的直接偏好(DPO),以处理与模型响应质量有关的边缘案例,从而有效地在智能和对话模型功能的功能之间取得了良好的平衡。这些改进导致了该行业的领先通用聊天模式,并具有最先进的智能和图像理解。
表现
Llama 4 Maverick包含170亿个激活参数,128个专家和4000亿个甲甲,其以低于Llama 3.3 70B的价格提供了更高的质量。从下表可以看出,Llama 4 Maverick是同类产品中最好的多模式模型。它的性能超过了类似的模型,例如带有EN的GPT-4O和Gemini 2.0在编码和识别方面,编码和识别,多语言,长上下文和图像基准以及更大的DeepSeek v3.1竞争。
较小的Llama 4 Scout是一种通用模型,具有170亿个激活参数,16位专家和1009亿个总参数,可提供其类别中最先进的性能。 Llama 4 Scout将支持的背景从Llama 3的128K提高到了1000万个令牌的领先。这为应用程序摘要等应用程序提供了更多可能的可能性,解析了广泛的用户活动以实现个性化的任务,并指出了大型代码库。
Llama 4 Scout在训练和训练后都使用256K上下文长度,提供了强大的整体上下文功能的基本模型。在诸如在干草堆上找到针的活动中,该模型显示出令人信服的结果。
Llama 4结构的主要变化之一是使用相互关联通过扫描推理温度,没有出现位置的调节层,并增强了长期上下文化功能。该体系结构称为Irrope Architecture,在该体系结构中,我代表一个连贯的注意力层,它使其支持它支持长期目标,而无需限制上下文。绳索是指大多数层旋转位置的牙龈。
Meta在图像和视频帧中广泛训练了这两个模型仍然图像,以使它们具有广泛的视觉理解,包括了解时序活动和相关图像。这使模型可以轻松地执行具有多图像输入和文本信号的视觉推理和理解任务。这些模型在假装过程中最多支持48张图像,并且可以在训练后支持8张图像,并取得出色的结果。
Llama 4侦察兵不仅仅是定位图像,还将用户信号与相关的视觉概念和模型模型的响应对齐图像中的区域。这允许大型语言模型精确地执行视觉Q&Amore,最好了解用户的目标并找到有趣的事物。
此外,Llama 4 Scout不仅仅是相似的编码模型,推论,长上下文和图像基准,而且比以前的Llama模型更好。
推动新范围推送骆驼:2T庞然大物
Llama 4庞然大物的预览是一种教师模型和专门的多模式混合模型,具有2880亿个激活参数,16位专家和约2万亿个参数。
它在数学,多语言和图像基准中提供了非熟思模型的最先进性能,非常适合教较小的骆驼模型4。
培训后具有两万亿个参数的模型是一个巨大的挑战,它要求研究人员完全重新设计和改善从数据量表开始的现行程序。为了最大程度地提高性能,元必须修剪95%的管理曲调(SFT)数据对于较小型号的d到50%的修剪比。此举是为了在质量和效率之间达到所需的平衡。 Meta还发现,轻巧的微调(SFT)第一和大型增强研究(RL)可以显着提高对模型能力和编码的认识。
META的强化学习方法(RL)通过接触策略模型,增加难度增加的提示,以及在发展逐渐增加难度的培训课程中,重点关注@K评论的通过。此外,在训练过程中,零效率线索是动态过滤的,并且已经建立了许多包含许多您的培训的培训,这在数学,推理和编码方面为模型带来了显着改善的性能。最后,从多个系统指令中猛烈抨击对于确保模型保持遵守理解和编码任务的坚持至关重要,从而使模型可以执行在各种任务中很好。
扩大研究(RL)研究的研究(RL)也是一个主要的挑战,迫使元元素重新设计和改善刺激强化以应对前所未有的规模的基础结构。
元将优化混合专家(MOE)的相似性以提高速度,从而加速差异过程。此外,他们在在线研究上开发了一个完全不寻常的培训框架,以改善技能。与现有的分布式培训框架相比,牺牲内存以将所有模型加载到内存中,新的元基础架构可以灵活地在不同的GPU中提供不同的模型,并且基于计算速度的许多模型之间的资源平衡和资源平衡。与上一代相比,这种创新的培训效率提高了近10倍。
Llama 4 Scout和Llama 4 Maverick现在可以下载到:
llama.com:https://www.llama.com/llama-lane下载/
拥抱面孔地址:https://huggingface.co/meta-llama
参考参考:https://ai.meta.com/blog/llama-4-gultimodal-telligence/return to sohu以查看更多信息 上一篇:Lei Jun在安静几天后讲话:小米通过了15年的企业
下一篇:没有了
下一篇:没有了
相关文章
- 2025-04-08元深夜开源骆驼4! Moe是第一次采用的,
- 2025-04-07Lei Jun在安静几天后讲话:小米通过了15年
- 2025-04-06选择了“天国:拯救2”!巴夫塔(Baaft
- 2025-04-05引入了Chen Geng
- 2025-04-04填写茶的进口指南:信息和保存